

知识图谱之同义词近义词query扩展挖掘
发布时间:2024-07-29 16:02 浏览次数:次 作者:佚名
在同义词近义词query扩展方向,总结了以下博主的调研内容,目前是当前较为新颖的方式:
同义词挖掘干货_JohnWSY的博客-CSDN博客_同义词挖掘算法
query归一 & 同义词挖掘_JohnWSY的博客-CSDN博客_同义词挖掘算法
技术解决方案上来看,第一是调取同义词词典或者接口有以下:
- oov or 垂直领域 or 新词:平行语料-语义对齐替换
- 平行语料query召回:通过 session-based 相似 query,多跳用户点击行为,拼音/繁对,最小编辑距离,构建 query-item_title,query-query,title-title。
- 抽取:抽取相同或相近上下文中的两个词语作为同义词对候,word2vec,skip-gram
- 排序-筛选:global and local 特征,统计特征、词语embedding相似度,term 间的 PMI ,文本相似度(编辑距离)以及人工筛选等方式进行过滤筛选,deep模型进行相似度排序
缺点:
- 1. 会挖掘出很多错误的同义词,尤其是当两个词比较短的情况下,比如“周杰伦”和“周杰”,就可能会被认为是同义词。所以这种方法适用于一些较长的文本,特别是专业词汇,术语。
- 2. 有可能是同位词、上下位词甚至是反义词,此时需要通过引入监督信号或外部知识来优化词向量,如有方法提出通过构建multi-task任务在预测目标词的同时,预测目标词在句子中表示的实体类型以加入实体的语义信息,类似感冒和发烧的症状作为补充,来提升词向量之间的语义相似性。
- 语义贡献网络的节点相似
- 语义共现网络本质是根据上下文构建的图,图中的节点是词,边是这个词的上下文相关词。对于语义共现网络的两个节点,如果这两个节点的共同邻居节点越多,说明这两个词的上下文越相似,是同义词的概率越大。
- 同义词簇归属预测
- 增强对知识图谱中已有同义词数据集的利用—entity synonym set,作者意在利用库中众多的同义词簇的整体分布,来评估实体词是否属于某一同义词簇Mining Entity Synonyms with Efficient Neural Set Generation.md
- 文本推断(阅读理解)
- 对于候选对是否是同义词,我们可以通过上下文作为推理的证据,构建prompt推理模板,A is commonly referred to B?预测 二分类问题
仅包含一个单一实体:相关性模型;基于term替换的完整的Query扩展技术路线可见下图
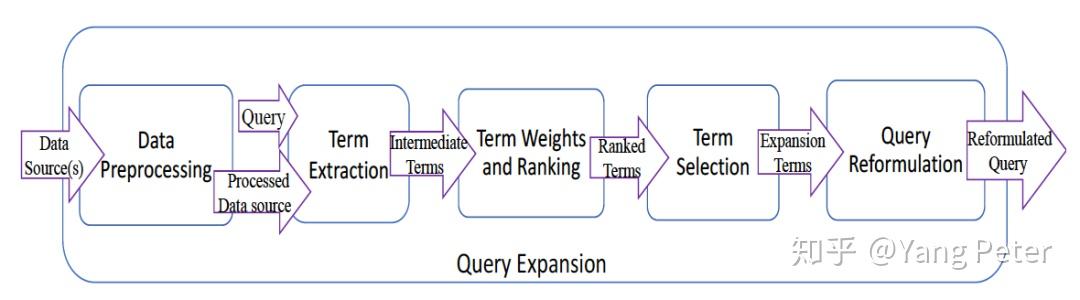
对原始Query首先需要做若干预处理,包括必要的纠错、补全,从Query中筛选出需要进行扩展的主题词或实体词,对最终的目标词完成扩展。这里我们着重关注 Expansion Terms 部分。
query候选:来自行为 or 事物本身语义
复杂语义考虑生成:再使用相关性模型做Query扩展可能会造成语义偏差过大的情况
- 多实体,不能分割开去理解,需要query embedding
- 标准化query
- session query集合
Query Expansion(扩充检索)和Query Suggestion(补全query) 是相关的query扩展的领域
- query embedding:word2vec,bert 等
- session query的发展:Learning to Attend, Copy, and Generate for Session-Basedery Suggestion,首先input端将编码整个search session,其次是在模型中加入attention和copy机制。这些可以说都是借鉴了文本摘要生成的一些技巧,这项task也比较类似,所以最终结果相较seq2seq是有所提升的
- multi-task:挖掘更多维度的特征,RIN: Reformulation Inference Network for Context-Aware Query Suggestion,整体架构是做了Candidate Query判别器、Query生成以及Query改写这三项任务的 Multi task,模型中增强了session中相邻Query的交互。重点是在feature部分,作者利用Query点击的网站,构建起了图结构,使用Node2Vec获得各节点的向量,将向量融合进了Query编码中。
- 强化学习:Ask the Right Questions: Active Question Reformulation with Reinforcement Learning,谷歌在 2018 ICLR 上发表的工作合并了使用序列模型完成Query改写,考虑使用强化学习来进一步增强,这个方案的大致思路是,模型与索引系统连接,若改写后的Query可以索引出排序更靠前的内容,则给予强化模型正向的激励。而且,train好的强化模型也可以倒过来finetune改写模型。
 上一篇
上一篇 









